

 如果结果不匹配,请
如果结果不匹配,请 

 更多“对两个包含解释变量个数不同的回归模型进行拟合优度比较时,应比…”相关的问题
更多“对两个包含解释变量个数不同的回归模型进行拟合优度比较时,应比…”相关的问题
利用BWGHT2.RAW中的数据。
(i)估计模型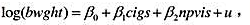 并按照通常的方式报告估计方程,包括样本容量和R²。斜率系数的符号与你的预期一致吗?请加以解释。
并按照通常的方式报告估计方程,包括样本容量和R²。斜率系数的符号与你的预期一致吗?请加以解释。
(ii)如果npvis增加一个样本标准差,对出生重量(bwght)有什么影响?
(iii)现在做log(bwght)对cigs的简单回归,并将斜率系数与第(i)部分中得到的估计值进行比较。估计出来吸烟的效应是否和第(i)部分的有明显差别?
(iv)找出cigs和npvis之间的系数,并用它来解释简单回归和多元回归下β1估计值的相似性。
(v)向第(i)部分的回归方程中加入变量mage,meduc,fage和feduc。出生体重[更确切地说是log(bwght)]是一个容易解释的变量吗?

其中,因为滞后支出变量,第一个可用年份(基年)是1993年。
(i)用混合OLS估计模型,并报告通常的标准误。为使得ai的期望值可以非零,你应该与年度虚拟变量一起包含一个截距项。支出变量的估计效应是什么?求OLS残差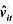 。
。
(ii)lunchit系数的符号在意料之中吗?解释系数的大小。你认为学区的贫穷率对考试通过率有很大的影响吗?
(iii)利用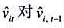 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
(iv)现在用固定效应法估计方程。滞后的支出变量仍显著吗?
(v)你为什么认为在固定效应估计中,注册学生人数和午餐项目变量不是联合显著的?
(vi)定义支出的总(或长期)效应为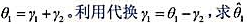 的标准误。
的标准误。
利用TWOYEAR.RAW中的数据。
(i)变量stotal是一项标准化测试变量,可用作无法观测的能力的代理变量。求stotal的样本均值和标准差。
(ii)做警察和univ对stotal的简单回归。两个大学教育变量都与stotal统计相关吗?请解释。
(iii)在教材方程(4.17)中增加stotal,并检验二年制大专和四年制大学教育具有相同回报的假设,备择假设是四年制大学的回报更高。你的结论与4.4节中的结论有何区别?
(iv)在第(iii)部分估计的方程中增加stotal2。测试分数变量的二次项有必要吗?
(v)在第(iii)部分的方程中增加stotal·警察和stotal·univ。这两项联合显著吗?
(vi)你通过使用stotal而控制能力变量的最终模型是什么?说明你的理由。
(i)用OLS估计以下模型
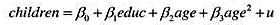
并解释估计值。特别是,固定age不变,多受一年教育对生育率的影响估计是多少?如果100位妇女再多受一年教育,预期她们的孩子数目将减少多少?
(ii)frsthalf是虚拟变量,若该妇女在上半年内分娩则取值1。假定frsthalf与第(i)部分中的误差项不相关,说明frsthalf是educ的一个合理的Ⅳ备选。(提示:你需要做一次回归。)
(iii)通过用frsthalf作为educ的Ⅳ,估计第(i)部分中的模型。将所估计的教育影响与第(i)部分中得到的OLS估计值进行比较。
(iv)在模型中增添二值变量electric、tv和bicycle。假定它们都是外生的。用OLS和2SLS估计方程,并比较educ的估计系数。解释tv的系数,以及为什么拥有电视对生育率有负效应。
数据集401KSUBS.RAW包含了净金融财富(nenfa)、被调查者年龄(age)、家庭年收入(inc)、家庭规模(fsize)方面的信息,以及参与美国个人的特定养老金计划方面的信息。财富和收入变量都以千美元为单位记录。对于这里的问题,只使用无子女已婚者数据(marr=1,fsize=2)。
(i)数据集中有多少无子女已婚夫妇?
(ii)利用OLS估计模型
nettfa=β0+β1inc+β2age+u;
并以常用格式报告结果。解释斜率系数。斜率估计值有何惊人之处吗?
(iii)第(ii)部分的回归截距有重要意义吗?请解释。
(iv)在1%的显著性水平上,针对H0:β2>1检验H0: β2=1,求出p值。你能拒绝H0吗?
(V)如果你做一个nettfa对inc的简单回归,inc的斜率估计值与第(ii)部分的估计值有很大不同吗?为什么?
A.无偏且一致
B.无偏但不一致
C.有偏但一致
D.有偏且不一致
利用WAGEPAN中数据。
(i)利用混合最小二乘法(pooledOLS)估计一个log(ag为被解释变量的方程。以educ,black,exper,married,union以及一系列时间虚拟变量(以1980年为基年)为可解释变量,解释及讨论变量married和union的系数。
(ii)解释为什么通常(i)中标准误总是偏小。算出关于married和union两个变量对自相关和异方差一稳健的标准误。
(iii)现在对变量lwage,exper,married和union进行一阶差分。(不随时间改变的变量educ,black和hisp被排除在这个估计之外,exper也是,因为它总是随着年份增加。)注意排除首年即1980年的一阶差分,因为不存在更早的年份。
(iv)就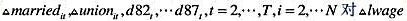 作回归分析,确保包括一个常数项和一个从1982年到1987年的时间虚拟变量。算出Δmarried和Δunion的系数和标准误。
作回归分析,确保包括一个常数项和一个从1982年到1987年的时间虚拟变量。算出Δmarried和Δunion的系数和标准误。
(v)对比婚姻状况和工会保费的估计水平及其一阶差分估计,并作相应评论。
为了检验抵押贷款市场中的歧视,可使用一个线性概率模型:
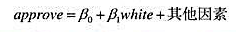
(i)如果对少数民族存在歧视,并控制了适当的因素,那么,的符号是什么?
(ii)将qpxe对white做回归,并以通常的形式报告结果。解释white的系数。它是统计显著的吗?它实际上大吗?
(iii)作为控制因素,增加变量hrat,obrat,loanprc,unem,male,married,dep,sch,cosign,chist,pubrec,mortlatl,mortlat2和vr。white的系数会有什么变化?仍有对非白人存在歧视的证据吗?
(iv)现在容许种族效应与度量了其他债务占收入比例的变量(obrat)存在着交互作用。交互项显著吗?
(v)利用第(iv)部分的模型,当债务负担达到样本均值obrat=32时,作为白人对贷款许可的概率有多大的影响?构造这种影响的一个95%的置信区间。
















