

 如果结果不匹配,请
如果结果不匹配,请 

 更多“大数据高线处理方案架构中,批处理引擎用于实现高性能的离线批处…”相关的问题
更多“大数据高线处理方案架构中,批处理引擎用于实现高性能的离线批处…”相关的问题
A.Hive
B.SparkSQL
C.Spark
D.MapReduce
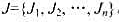 .每个作业Ji都有2项任务分别在2台机器上完成.每个作业必须先由机器1处理,再由机器2处理.作业Ji需要机器j的处理时间为tij(=1,2,...,n;j=1,2).对于一个确定的作业调度,设Fij是作业i在机器j上完成处理的时间.所有作业在机器2上完成处理的时间和
.每个作业Ji都有2项任务分别在2台机器上完成.每个作业必须先由机器1处理,再由机器2处理.作业Ji需要机器j的处理时间为tij(=1,2,...,n;j=1,2).对于一个确定的作业调度,设Fij是作业i在机器j上完成处理的时间.所有作业在机器2上完成处理的时间和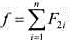 称为该作业调度的完成时间和.
称为该作业调度的完成时间和.批处理作业调度问题要求对于给定的n个作业,制定最佳作业调度方案,使其完成时间和达到最小.
算法设计:对于给定的n个作业,计算最佳作业调度方案.
数据输入:由文件input.txt提供输入数据.文件第1行有1个正整数n,表示作业数.接下来的n行中,每行有2个正整数i和j,分别表示在机器1和机器2上完成该作业所需的处理时间.
结果输出:将最佳作业调度方案及其完成时间和输出到文件output.txt.文件的第1行是完成时间和,第2行是最佳作业调度方案.

B.Carbon使用轻量级压缩和重量级压缩的组合压缩算法压缩数据,可以减少60%-80%数据存储空间,大大节省硬件存储成本
C.Carbon是一种新型的ApacheHadoop本地文件格式,使用先进的列式存储.索引.压缩和编码技术,以提高计算效率,有助于加速超过PB数量级的数据查询,可用于更换的交互查询
D.Carbon也是一种将数据源与Spark集成的高性能分析引擎
A.企业对联盟的控制力较强
B.更具有战略联盟的本质特征
C.有利于企业长久合作
D.有利于扩大企业资金实力
A.这种操作太麻烦,很多人不会
B.这种存储引擎会因为断电或者程序退出丢失数据
C.这种存储引擎是将数据存在内存里面的,内存容量不够用,存不了太多的数据
D.高并发的数据有可以替代的处理方式,用这种存储引擎没有必要
















