

 如果结果不匹配,请
如果结果不匹配,请 

 更多“对于总体线性回归模型Yi=β0+β1X1i+β2X2i+β3…”相关的问题
更多“对于总体线性回归模型Yi=β0+β1X1i+β2X2i+β3…”相关的问题
A、E(ut)=0
B、var(ut)=σ2
C、cov(ut,us)=0
D、cov(xt,ut)=0
E、ut服从分布N(0,σ2)
考虑简单回归模型
y=β0+β1x+u
令z为x的二值工具变量。运用教材(15.0),证明Ⅳ估计量β1可以写成: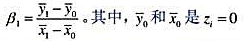 的那部分样本中yi和xi的样本平均值,而
的那部分样本中yi和xi的样本平均值,而 的样本平均值。该估计量称为群组估计量,它是由沃德(Wald,1940)最先提出。
的样本平均值。该估计量称为群组估计量,它是由沃德(Wald,1940)最先提出。
(1)如果真实的模型是Yi=β1Xi+μi,但你却拟合了一个带截距项的模型Yi=α0+α1Xi+νi,试评述这一设定误差的后果。
(2)在(1)中,假设真实的模型是带截距项的模型,而你却对过原点的模型进行了普通最小二乘回归。请评述这一模型误设的后果。
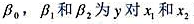 回归的OLS估计量。(给定样本中自变量的值)证明β1的期望值是
回归的OLS估计量。(给定样本中自变量的值)证明β1的期望值是
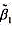 表示通过假定截距为零而得到的β1的估计量。
表示通过假定截距为零而得到的β1的估计量。
(i)在前4个高斯-马尔科夫假定之下,考虑简单回归模型y=β0+β1x+u对某个函数g(x),比如g(x)=x2或g(x)=log(1+x2)。定义zi=g(xi)定义一个斜率估计量为
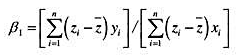
证明β1是线性无偏的。记住,在你的推导过程中,因为E(ulx)=0,所以你可以把x和z,都看成非随机的。
(ii)增加同方差假定MLR.5,证明
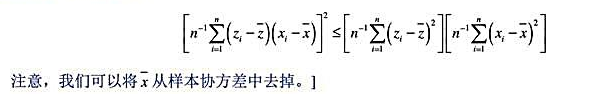
(iii)在高斯-马尔科夫假定下,直接证明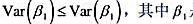 是OLS估计量。
是OLS估计量。
A.无偏且一致
B.无偏但不一致
C.有偏但一致
D.有偏且不一致
A、Y与lnX是线性的
B、Y与X是非线性的
C、lnY与β1是线性的
D、Y与β1是非线性的
E、lnY与lnX是线性的
数据集401KSUBS.RAW包含了净金融财富(nenfa)、被调查者年龄(age)、家庭年收入(inc)、家庭规模(fsize)方面的信息,以及参与美国个人的特定养老金计划方面的信息。财富和收入变量都以千美元为单位记录。对于这里的问题,只使用无子女已婚者数据(marr=1,fsize=2)。
(i)数据集中有多少无子女已婚夫妇?
(ii)利用OLS估计模型
nettfa=β0+β1inc+β2age+u;
并以常用格式报告结果。解释斜率系数。斜率估计值有何惊人之处吗?
(iii)第(ii)部分的回归截距有重要意义吗?请解释。
(iv)在1%的显著性水平上,针对H0:β2>1检验H0: β2=1,求出p值。你能拒绝H0吗?
(V)如果你做一个nettfa对inc的简单回归,inc的斜率估计值与第(ii)部分的估计值有很大不同吗?为什么?
















