

 如果结果不匹配,请
如果结果不匹配,请 

 更多“如果SVM模型欠拟合,可以增大惩罚参数C的值。()”相关的问题
更多“如果SVM模型欠拟合,可以增大惩罚参数C的值。()”相关的问题
A.L2范数可以防止过拟合,提升模型的泛化能力。但L1正则做不到这一点
B.L2正则化标识各个参数的平方的和的开方值
C.L2正则化有个名称叫“Lassoregularization”
D.L1范数会使权值稀疏
1952年--1997年我国人均国内生产总值(单位:元)数据如表8.3所列。
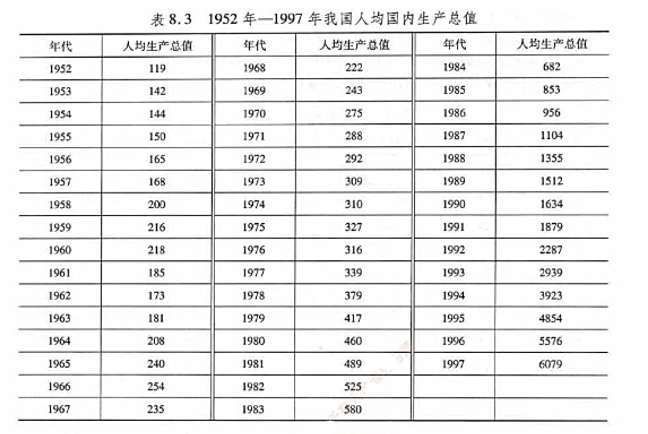 (1)用ARIMA(2,1,1)模型拟合,求模型参数的估计值;
(1)用ARIMA(2,1,1)模型拟合,求模型参数的估计值;
(2)求数据的10步预报值。
(1)如果真实的模型是Yi=β1Xi+μi,但你却拟合了一个带截距项的模型Yi=α0+α1Xi+νi,试评述这一设定误差的后果。
(2)在(1)中,假设真实的模型是带截距项的模型,而你却对过原点的模型进行了普通最小二乘回归。请评述这一模型误设的后果。
A.数据集合扩充
B.L1和L3正则化
C.提前停止训练
D.使用Dropout方法
在10.3节酶促反应中,如果用指数增长模型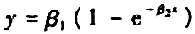 代替Michals-Menten模型对经过嘌呤霉素处理的实验数据作非线性回归分析.其结果将如何?更进一步,若选用模型
代替Michals-Menten模型对经过嘌呤霉素处理的实验数据作非线性回归分析.其结果将如何?更进一步,若选用模型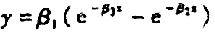 来拟合相同的数据,其结果是否比指数增长模型有所改进?试作出模型的残差图进行比较。
来拟合相同的数据,其结果是否比指数增长模型有所改进?试作出模型的残差图进行比较。
A.通过正则化可以减少网络参数的个数,一定程度可能增加过拟合
B.利用L1或L2正则化可以使权重衰减,从而一定程度上减少过拟合
C.在神经网络训练过程中类似dropout减少神经元或相关链接权的数量
D.通过增加数据扰动的数据增强减少了神经网络的过拟合
A.不同剂量的血药浓度一时间曲线相互平行,表明在该剂量范围内为线性动力学过程,反之则为非线性动力学过程
B.以剂量对相应的血药浓度进行归一化,以单位剂量下血药浓度对时间作图,所得的曲线如明显不重叠,则可能存在非线性过程
C.AUC分别除以相应的剂量,如果所得比值明显不同,则可能存在非线性过程
D.将每个剂量的血药浓度一时间数据按线性动力学模型处理,若所求得的动力学参数(t1/2、k、C1等)明显地随剂量大小而改变,则可能存在非线性过程
E.一旦消除过程在高浓度下达到饱和,则血药浓度会急剧增大;当血药浓度下降到一定值时,药物消除速度与血药浓度成正比,表现为非线性动力学特征
















