


 如果结果不匹配,请
如果结果不匹配,请 

 更多“本题使用CRIME 3.RAW中的数据。(iii)估计第(i…”相关的问题
更多“本题使用CRIME 3.RAW中的数据。(iii)估计第(i…”相关的问题
在例11.6中,我们估计了一个一阶差分形式的有限分布滞后模型:
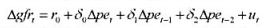
利用FERTIL 3.RAW中的数据来检验误差中是否存在AR(1) 序列相关。
本题使用WAGE2.RAW中的数据。一般地,保证如下所有回归都含有截距。
(i)将IQ对educ进行简单回归,并得到斜率系数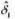

本题利用WAGE1.RAW中的数据。
(i)使用OLS估计方程

(iv)exper取什么值时,工作经历的增加实际上会降低预期的log(wage)。样本中有多少人具有比该取值更长的工作经历?
e232是232部门中平均工资的月增长率(以对数形式变化) , gemp232是232部门中的就业增长率, gmwage是联邦最低工资的增长率, gcpi是(城市) 消费者价格指数的增长率。
(i)求gwage232中的一阶自相关。这个序列看起来是弱相关的吗?

本题使用INFMRT.RAW中1990年的数据。
(i)重新估计方程(9.43),但现在对哥伦比亚特区这个观测引进一个虚拟变量(记为DC)。解释DC的系数,并评论其大小和显著性。
(ii)将第(i)步所得到的估计值和标准误与方程(9.44)中的估计值和标准误相比较。根据这种对单个观测引进一个虚拟变量的做法,你得到什么结论?
本题利用PHILLIPS.RAW中的数据。现在你应该使用56年的数据。
(i)重新估计方程(11.19),并以通常格式报告结果。当你增加近几年的数据之后,截距和斜率估计值有明显变化吗?
(ii)求自然失业率的新估计值。将这个新估计值与例11.5中的估计值进行比较。
(iii)计算unem的一阶自相关系数。按照你的观点, 单位根接近于1吗?
(iv)利用A mem取代unem作为解释变量。哪个解释变量具有更高的R?
本题要用到MLB1.RAW中的数据。
(i)使用方程(4.31)中所估计的模型,并去掉变量rbisyr。hrunsyr的统计显著性会怎么样?hrunsyr的系数大小又会怎么样?
(ii)在第(i) 部分的模型中增加变量runsyr(每年垒得分),fldperc(防备率)和sbasesyr(每年盗垒数) 。这些因素中,哪一个是个别显著的?
(iii)在第(ii)部分的模型中, 检验bavg, fldperc和sbasesyr的联合显著性。
本题使用JTRAIN.RAW中的数据。
(i)考虑简单回归模型
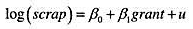
其中,scrap表示企业的废品率,grant表示是否得到工作培训津贴的一个虚拟变量。你能想到u中的无法观测因素可能会与grant相关的原因吗?
(ii)利用1988年的数据估计这个简单的回归模型。(你应该有54个观测。)得到工作培训津贴显著地降低了企业的废品率吗?
(iii)现在增加一个解释变量log(scrap87)。这将如何改变grant的估计影响?解释grant的系数。相对于单侧备择假设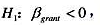 它在5%的显著性水平上统计显著吗?
它在5%的显著性水平上统计显著吗?
(iv)相对双侧备择假设,检验log(scrapg)的参数为1的虚拟假设。报告检验的P值。
(v)利用异方差-稳健标准误,重复第(iii)步和第(iv)步,并简要讨论任何明显的差异。
本题利用HSE IN V.RAW中的数据。
(i)求出log(in vpc) 中的一阶自相关系数, 然后再求log(im pc) 除掉线性趋势后的自相关。对log(price) 做相同的计算。这两个序列中的哪个可能有单位根?
(ii)基于第(i)部分的结论估计方程:
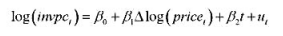
并以标准形式报告结果。对系数β1作出解释,并判断它是否统计显著。
(iii)除掉log(inypc) 的线性趋势,然后在第(ii)部分的回归方程中使用除趋势的因变量(见10.5节), R2有何变化?
(iv)现在用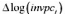 作因变量。结果与第(ii) 部分相比有何不同?时间趋势还是显著的吗?为什么是 或不是?
作因变量。结果与第(ii) 部分相比有何不同?时间趋势还是显著的吗?为什么是 或不是?
利用MEAP00 O1中的数据回答本题。
(i)使用OLS估计模型
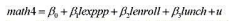
并用通常的格式报告你的结论。在5%的显著性水平上,每个解释变量都是统计显著的吗?
(ii)求出第(i) 部分中回归的拟合值。拟合值的取值范围是多少?它与math4的实际数据取值范围相比如何?
(iii)求出第(i)部分中回归的残差。哪类学校具有最大的(正)残差?对这个残差给予解释。
(iv)在方程中增加所有解释变量的平方项,检验它们的联合显著性。你会把它们放到模型中吗?
(v)回到第(i)部分中的模型,将因变量和每个解释变量都除以各自的样本标准差,并重新进行回归。(除非你还将每个变量分别减去了各自的均值,否则还应该包括一个截距项。)以标准差为单位,哪个解释变量对数学考试通过率具有最大的影响?
本题使用GPA2.RAW中的数据。
(i)考虑方程
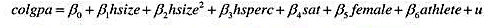
其中,colgpa表示累积的大学GPA,hsize表示高中毕业年级以百人计的规模,hsperc表示在毕业年级中学术排名的百分位,sat表示SAT综合分数,female是一个二值变量,而athlete也是一个运动员取值1的二值变量。你对这个方程中的系数有何预期?哪些你没有把握?
(ii)估计第(i)部分中的方程,并以通常的形式报告结果。估计运动员和非运动员之间GPA的差异是多少?它是统计显著的吗?
(ii)从模型中去掉sat并重新估计这个方程。现在,作为运动员的估计影响是多大?讨论为什么这个估计值不同于第(ii)部分的结论。
(iv)在第(i)部分的模型中,容许作为运动员的影响会因性别不同而不同。检验如下原假设:在其他条件不变的情况下,女生是否是运动员没有差别。
(v)sat对colgpa的影响会因性别不同而不同吗?讲出你的根据。
















