 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
本题使用HTV.RAW中的数据。(i) 将log(wage) 对educ进行简单的OLS回归。在不控制其他因素的情况
本题使用HTV.RAW中的数据。(i) 将log(wage) 对educ进行简单的OLS回归。在不控制其他因素的情况
本题使用HTV.RAW中的数据。
(i) 将log(wage) 对educ进行简单的OLS回归。在不控制其他因素的情况下, 多接受一年教育的估计回报的95%置信区问是什么?
(ii) 变量c til(以千美元为单位) 是17~18岁的学生面临的学费变化。证明educ和ctu it基本上是不相关的。这对一个简单回归分析中ctu it作为educ的一个可能的工具有何含义?
(iii)现在,在第(i)部分的简单回归模型中引人工作经历的二次函数以及当前居住地和18岁时的居住地等一整套区域虚拟变量集。模型中还包含个人当前居住地和18岁时居住地的城市指标。多受一年教育的估计回报是多少?
(iv) 再次利用ctu it作为edic的潜在工具变量, 估计educ的约简型。[当然, 现在educ的约简型也包含第(iii)部分中的解释变量。] 证明ctu it在educ的约简型中是统计显著的。
(v) 把ctu it作为educ的工具变量, 用Ⅳ估计第(iii) 部分中的模型。教育回报的置信区间与第(iii) 部分中的OLS置信区间相比如何?
(vi)你认为第(v)部分中的ⅣV程序令人信服吗?
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案


 更多“本题使用HTV.RAW中的数据。(i) 将log(wage)…”相关的问题
更多“本题使用HTV.RAW中的数据。(i) 将log(wage)…”相关的问题
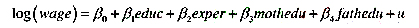
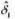




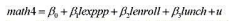
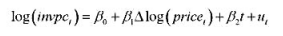
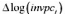 作因变量。结果与第(ii) 部分相比有何不同?时间趋势还是显著的吗?为什么是 或不是?
作因变量。结果与第(ii) 部分相比有何不同?时间趋势还是显著的吗?为什么是 或不是?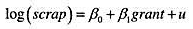
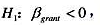 它在5%的显著性水平上统计显著吗?
它在5%的显著性水平上统计显著吗?















