

 如果结果不匹配,请
如果结果不匹配,请 

 更多“(i)在计算机习题C7.5所估计的模型中, 应用方程(9.3…”相关的问题
更多“(i)在计算机习题C7.5所估计的模型中, 应用方程(9.3…”相关的问题
使用LOANAPP.RAW中的数据。
(i)有多少个观测的obrat>40,即其他债务负担超过其总收入的40%?
(ii)在第7章的计算机练习C8中,去掉obrat>40的观测,重新估计第(ii)部分中的模型。white的系数估计值和:统计量将会怎样?
(ii)βwhite看起来对所使用的样本过度敏感吗?
间和工作时间之间的取舍,并考察影响睡眠的其他因素:
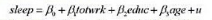
其中,sleep和totwrk都以分钟/周为单位,而educ和age则以年为单位。(也可参见计算机习题C2.3。)
(i)如果成年人为工作而放弃睡眠,β1的符号是什么?
(ii)你认为β2和β3的符号应该是什么?
(iii)利用SLEEP75.RAW中的数据, 估计出来的方程是
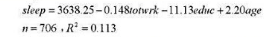
如果有人一周多工作5个小时,预计sleep会减少多少分钟?这是一个很大的舍弃吗?
(iv)讨论educ的估计系数的符号和大小。
(v)你能说totwrk,educ和age解释了sleep的大部分变异吗?还有什么其他因素可能影响花在睡眠上的时间?它们与totwrk可能相关吗?
)序列相关。
(ii)如果你发现有序列相关的证据,用科克伦-奥卡特方法重新估计这个方程,并将所得结果与以前的结果进行比较。
利用LOANAPPRAW中的数据;也可参见第7章的计算机练习C8。
(i)估计一个approve对white的概率单位模型。求出白人和黑人贷款许可的估计概率。与线性概率估计值相比如何?
(ii)现在在这个概率单位模型中增加变量hrat、obrat、loanpre、unem、male、married、dep、sch、cosign、chist、pubrec、mortlatl、mortlat2和vr。有对非白人歧视的统计上显著的证据吗?
(iii)用对数单位估计模型的第(ii)部分,将white的系数与概率单位估计值相比较。
(iv)使用教材方程(17.17)估计在概率单位模型和对数单位模型中歧视效应的大小。
利用DISCRIM.RAW中的数据回答本题。(也可参见第3章计算机练习C8。)
(i)利用OLS估计模型
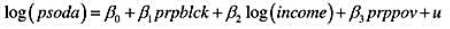
以常用形式报告结果。在5%的显著性水平上,相对一个双侧备择假设,β统计显著异于零吗?在1%的显著性水平上呢?
(ii)log(income)和prppov的相关系数是多少?每个变量都是统计显著的吗?报告双侧P值。
(iii)在第(i)部分的回归中增加变量log(hseval)。解释其系数并报告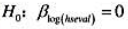 的双侧p值。
的双侧p值。
(iv)在第(ii)部分的回归中,log(income)和prppov的个别统计显著性有何变化?这些变量联合显著吗?(计算一个p值。)你如何解释你的答案?
(v)给定前面的回归结果,在确定一个地区的种族构成是否影响当地快餐价格时,你会报告哪一个结果才最为可靠?
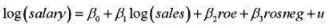
讨论对 的解释及其统计显著性。
的解释及其统计显著性。
(i)用OLS估计以下模型
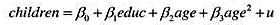
并解释估计值。特别是,固定age不变,多受一年教育对生育率的影响估计是多少?如果100位妇女再多受一年教育,预期她们的孩子数目将减少多少?
(ii)frsthalf是虚拟变量,若该妇女在上半年内分娩则取值1。假定frsthalf与第(i)部分中的误差项不相关,说明frsthalf是educ的一个合理的Ⅳ备选。(提示:你需要做一次回归。)
(iii)通过用frsthalf作为educ的Ⅳ,估计第(i)部分中的模型。将所估计的教育影响与第(i)部分中得到的OLS估计值进行比较。
(iv)在模型中增添二值变量electric、tv和bicycle。假定它们都是外生的。用OLS和2SLS估计方程,并比较educ的估计系数。解释tv的系数,以及为什么拥有电视对生育率有负效应。
利用SLEEP 75.RAW中的数据(也可参见习题3.3) , 我们得到如下估计方程

变量sleep是每周晚上睡眠的总分钟数, ton work是每周花在工作上的总分钟数, educ和age则以年为单位,而male是一个性别虚拟变量。
(i)所有其他因素不变,有没有男性比女性睡眠更多的证据?这个证据有多强?
(ii)工作与睡眠之问有统计显著的取舍关系吗?所估计的取舍关系是什么样的?
(iii)为了检验年龄在其他因素不变的情况下对睡眠没有影响这个虚拟假设,你还需要另外做什么回归?
利用数据集GPA1.RAW。
(i)利用OLS估计一个将colGPA与hsGPA,ACT,skipped和PC相联系的模型。求OLS残差。
(ii)计算异方差性的怀特检验特殊情形。在对colGPA,和colGPA,的回归中,求拟合值。
(iii)验证第(ii)部分得到的拟合值都严格为正。然后利用权数1/h求加权最小二乘估计值。根据对应的OLS估计值,将逃课和拥有计算机之影响的加权最小二乘估计值与对应OLS估计值相比较。它们的统计显著性如何?
(iv)在第(iii)部分的WLS估计中,求异方差-稳健的标准误。换言之,容许第(ii)部分中所估计的方差函数可能误设(参见问题8.4)。标准误与第(iii)部分相比有很大变化吗?
考虑一个雇员水平的模型
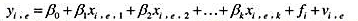
其中无法观测变量f是在一个给定的企业i内,对每个雇员的“企业效应”。误差项vi,e是企业i中雇员e所独具的。诸如方程(8.28)中的综合误差就是ui,e=fi+ui,e.

(iv)讨论第(ii)部分对于利用企业层次的平均数据进行WLS估计的意义,其中第i次观测所用的权数就是通常的企业规模。
利用PHILLIPS.RAW中的数据。
(i)用直至1997年的数据估计教材(18.48)和(18.49)中的模型。参数估计值与教材(18.48)和教材(18.49)中的结果相比有很大不同吗?
(ii)用新方程预测unem1998,小数点后保留两位数。哪个方程预测得更好?
(ii)我们在正文中讨论过,用教材(18.49)预测unem1998为4.90.把它与利用直至1997年的数据得到的预测相比较。多用一年数据求得的参数估计值能给出更好的预测吗?
(iv)用教材(18.48)中估计的模型求出unem的提前两期预测值。即利用α=1.572,p=0.732,h=2时的教材方程(18.55)预测unem与把unem1997=4.9代入教材(18.48)所得到的提前一期预测值相比,哪一个更好?
















