

 如果结果不匹配,请
如果结果不匹配,请 

 更多“用来识别显著关联项的数据,应该基于受访者对开放式问题回答的情…”相关的问题
更多“用来识别显著关联项的数据,应该基于受访者对开放式问题回答的情…”相关的问题
A.能够基于统计特征和关联特征识别应用
B.能够区分应用的不同功能,例如区分网盘类应用的上传和下载
C.识别数量超过6000
D.应用特征发生变化时,需要升级防火墙软件
A.过程方法
B.管理的系统方法
C.持续改进
D.基于事实的决策方法
使用BWGHT2.RAW中的数据。
(i)用OLS估计方程
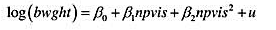
并按照通常的格式报告结果。二次项显著吗?
(ii)基于第(i)部分中的方程,证明:最大化log(bwght)的产前检查次数约为22。样本中有多少妇女至少接受过22次产前检查?
(ii)在22次产前检查之后,预计婴儿出生体重实际上会下降,这有意义吗?请解释。
(iv)在方程中增加母亲年龄,并使用二次函数形式。保持npvis不变,目前在什么年龄,孩子的出生体重最大?样本中有多大比例的妇女年龄大于这个“最优”生育年龄。
(v)你认为母亲年龄和产前检查次数解释了log(bwght)中的大部分变化吗?
(vi)利用npvis和age的二次方程,确定用bwght的自然对数或水平值来预测bwght孰优孰劣。
A.NaiveBayes朴素贝叶斯算法
B.Pearson趋势关联分析+K-means自学习聚类
C.基于PNN的神经网络算法
D.k均值聚类算法

其中,因为滞后支出变量,第一个可用年份(基年)是1993年。
(i)用混合OLS估计模型,并报告通常的标准误。为使得ai的期望值可以非零,你应该与年度虚拟变量一起包含一个截距项。支出变量的估计效应是什么?求OLS残差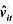 。
。
(ii)lunchit系数的符号在意料之中吗?解释系数的大小。你认为学区的贫穷率对考试通过率有很大的影响吗?
(iii)利用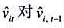 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
(iv)现在用固定效应法估计方程。滞后的支出变量仍显著吗?
(v)你为什么认为在固定效应估计中,注册学生人数和午餐项目变量不是联合显著的?
(vi)定义支出的总(或长期)效应为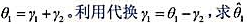 的标准误。
的标准误。
















