

 如果结果不匹配,请
如果结果不匹配,请 

 更多“在串的简单模式匹配中,当模式串位j与目标串位i比较时,两字符…”相关的问题
更多“在串的简单模式匹配中,当模式串位j与目标串位i比较时,两字符…”相关的问题
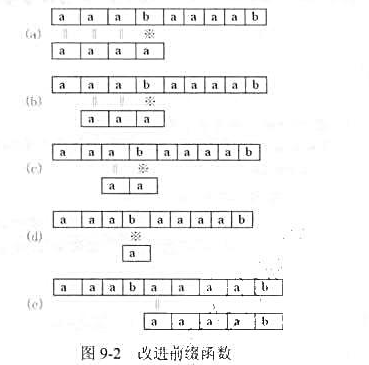
在图9-2(a)中匹配失败后,按前缀函数指示继续作了图(b)~(d)的比较后,最后在图(e)找到一个匹配.事实上,图(b)~(d)的比较都是多余的.因为模式串在位置0、1、2处的字符和位置3处的字符都相等,因此不需要再和主串中位置3处的字符比较,而可以将模式一次向右滑动4个字符,直接进入图(e)的比较.这就是说,在KMP算法中遇到p[j+1]≠t[i],且p[j+1]=p[next[j]+1]时,可一次向右滑动j-next[next[j]]个字符,而不是j-next[j]个字符.根据此观察,设计一个改进的前缀函数,使得遇到上述特殊情况时效率更高.
在模式枚举(pattern enumeration)类应用中,需要从主串T中找出所有的模式串P(T|=n,|P|=m),而且有时允许模式串的两次出现位置之间相距不足m个字符。
类似于教材310页图11.3中的实例,比如在“000000”中查找“000”。若限制多次出现的模式串之间至少相距|P|=3个字符,则应找到2处匹配;反之,若不作限制,则将找到4处匹配。
a)试举例说明,若采用后一约定,则教材11.4.3节BM算法的好后缀策略,可能需要Ω(nm)时间;
b)试针对这一缺陷改进好后缀策略,使之即便在采用后一约定时,最坏情况下也只需线性时间。
















