

 如果结果不匹配,请
如果结果不匹配,请 

 更多“假设你有一个非常大的训练集合,如下机器学习算法中,你觉着有哪…”相关的问题
更多“假设你有一个非常大的训练集合,如下机器学习算法中,你觉着有哪…”相关的问题
A.*
B.1
C.10
D.30010000
A.完成一个主题模型掌握语料库中最重要的词汇
B.训练袋N-gram模型捕捉顶尖的n-gram:词汇和短语
C.训练一个词向量模型学习复制句子中的语境
D.以上所有
利用GPA3.RAW中的数据,对秋季第二学期的学生估计如下方程

这里trm gpa表示木学期的GPA,crs gpa表示所修全部课程加权平均的GPA,crs gpa表示木学期前的GPA,tot hrs表示此学期前总学分,sat表示SAT分数, hs perc表示其在高中班级排名的百分位,female是一个性别虚拟变量,而season也是一个虚拟变量,并在该学生在秋季参加学生运动赛事时取值1.通常的标准误和异方差-稳健的标准误分别报告于圆括号和方括号中。
(i)变量cr gpa、cumgpa和tot hrs都有预期的估计效应吗?这些变量中有哪些在5%的显著性水平上是统计显著的?使用不同的标准误是否有什么影响?
(ii)为什么虚拟假设H0: 有意义?利用这两种标准误, 在5%的显著性水平上针对双侧对立假设检验这个虚拟假设。描述你的结论。
有意义?利用这两种标准误, 在5%的显著性水平上针对双侧对立假设检验这个虚拟假设。描述你的结论。
(iii)利用两种标准误来检验参加体育赛事对学期GPA是否有影响。拒绝虚拟假设的显著性水平与所用的标准误有关系吗?
如下模型可用来研究竞选支出如何影响选举结果:
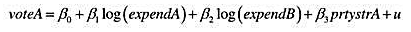
其中,voteA表示候选人A得到的选票百分数,expendA和expendB分
别表示候选人A和B的竞选支出,而prtystrA则是对A所在党派实力的一种度量(A所在党派在最近一次总统选举中获得的选票百分比)。
(i)如何解释β1?
(ii)用参数表述如下原假设:A的竞选支出提高1%被B的竞选支出提高1%所抵消。
(iii)利用VOTE1.RAW中的数据来估计上述模型,并以通常的方式报告结论。A的竞选支出会影响结果吗?B的支出呢?你能用这些结论来检验第(ii)部分中的假设吗?
(iv)估计一个模型,使之能直接给出检验第(ii)部分中假设所需用的:统计量。你有什么结论?(使用双侧备择假设。)
A.如果增加模型复杂度或核函数的多项式阶数,将会发生什么(A)
B.A导致过拟合
C.B导致欠拟合
D.C无影响,因为模型已达100%准确率
E.D以上均不正确

式中,trngpa表示本学期的GPA,crsgpa表示所修全部课程加权平均的GPA,cumgpa表示本学期前的GPA,tothrs表示此学期前总学分,sat表示SAT分数,hsperc表示其在高中班级排名的百分位,female是一个性别虚拟变量,而season也是一个虚拟变量,并在该学生在秋季参加学生运动赛事时取值1。通常的标准误和异方差-稳健的标准误分别报告于圆括号和方括号中。
(i)变量crsgpa、cungpa和tothrs都有预期的估计效应吗?这些变量中有哪些在5%的显著性水平上是统计显著的?使用不同的标准误是否有什么影响?
(ii)为什么虚拟假设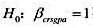 有意义?利用这两种标准误,在5%的显著性水平上针对双侧备择假设检验这个虚拟假设。描述你的结论。
有意义?利用这两种标准误,在5%的显著性水平上针对双侧备择假设检验这个虚拟假设。描述你的结论。
(iii)利用两种标准误来检验参加体育赛事对学期GPA是否有影响。拒绝原假设的显著性水平与所用的标准误有关系吗?
利用SLEEP 75.RAW中的数据(也可参见习题3.3) , 我们得到如下估计方程

变量sleep是每周晚上睡眠的总分钟数, ton work是每周花在工作上的总分钟数, educ和age则以年为单位,而male是一个性别虚拟变量。
(i)所有其他因素不变,有没有男性比女性睡眠更多的证据?这个证据有多强?
(ii)工作与睡眠之问有统计显著的取舍关系吗?所估计的取舍关系是什么样的?
(iii)为了检验年龄在其他因素不变的情况下对睡眠没有影响这个虚拟假设,你还需要另外做什么回归?
考虑一个教育回报取决于工作经历多少(反之亦然)的模型:
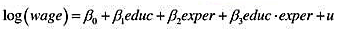
(i)证明:保持exper不变,多受一年教育的回报(以小数表示)是β1+β3exper。
(ii)陈述如下原假设:教育的回报并不取决于exper的水平。你认为合适的备择假设是什么?
(iii)利用WAGE2.RAW中的数据,相对你给出的备择假设来检验(ii)中的原假设。
(v)令θ1表示exper=10时(以小数表示)的教育回报:θ1+10β3求出β1的估计值及其95%的置信区间.(提示:写成θ1-10β3并代入方程,然后重新整理。这就给出了得到的θ1置信区间所需做的回归。)
















