

 如果结果不匹配,请
如果结果不匹配,请 

 更多“你在管理一个包含多阶段的项目,在每个阶段开始,都需要验证前一…”相关的问题
更多“你在管理一个包含多阶段的项目,在每个阶段开始,都需要验证前一…”相关的问题
多阶段抽样
A.是按一定的方式以同等的概率抽样
B.将抽样对象按次序编号,先随机抽取第一个调查对象,然后再按一定间隔随机抽样
C.先将总体按某种特征分成若干个“层”,再在每个层中用随机方式抽取调查对象,再将每个层所有抽取的对象合成一个样本
D.从总体中随机抽取若干群作为调查对象,然后对每个群中所有对象进行检查
E.在大规模调查中常把抽样过程分为几个阶段,每个阶段可单纯随机抽样
A.是按一定的方式以同等的概率抽样
B.将抽样对象按次序编号,先随机抽取第1个调查对象,然后再按一定间隔随机抽样
C.先将总体按某种特征分成若干个“层”,再在每个层中用随机方式抽取调查对象,再将每个层所有抽取的对象合成一个样本
D.从总体中随机抽取若干群作为调查对象,然后对每个群中所有对象进行检查
E.在大规模调查中常把抽样过程分为几个阶段,每个阶段可单纯随机抽样
111.整群抽样
112.机械抽样
113.分层抽样
114.多阶段抽样
115.单纯随机抽样
(i) 如果你利用一个容量为n的随机样本进行score。对voucheri的简单回归, 那么, 普通最小二乘估计量能给出教育券项目影响的一个无偏估计量吗?
(ii)假设你还可以搜集到一些诸如家庭收入、家庭结构(比如孩子是否与双亲住在一起)和父母的受教育水平等背景信息。为了得到教育券项目影响的无偏估计量,你需要控制这些因素吗?请解释。
(iii)你为什么应该在回归中包含这些家庭背景变量?有没有你不包含这些背景变量的情况呢?
A.不可抗力条款
B.天灾条款
C.减轻
D.片面沟通
A.项目成员的家属也可能成为项目干系人
B.整个项目周期中项目干系人都可能发生增减变化
C.规划干系人管理应由项目经理在项目规划阶段完成
D.应把干系人满意度作为一个关键的项目目标来管理
A.风险监控
B.进度控制
C.范围计划编制
D.范围变更控制
A.为DNS服务器创建一个新的作用域
B.创建一个DHCP服务器保留选项
C.配置005名服务器配置作用域选项
D.配置包含这四台DNS服务器IP地址的例外
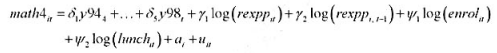
其中,因为滞后支出变量,第一个可用年份(基年)是1993年。
(i)用混合OLS估计模型, 并报告通常的标准误。为使得ai的期望值可以非零, 你应该与年度虚拟变量一起包含一个截距项。支出变量的估计效应是什么?求OLS残差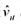 。
。
(ii)lunchit系数的符号在意料之中吗?解释系数的大小。你认为学区的贫穷率对考试通过率有很大的影响吗?
(iii)利用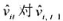 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
(iv)现在用固定效应法估计方程。滞后的支出变量仍显著吗?
(v)你为什么认为在固定效应估计中,注册学生人数和午餐项目变量不是联合显著的?

A.在起始授权机构(SOA)记录为区域设置减少重试时间间隔
B.在起始授权机构(SOA)记录为区域设置减少刷新时间间隔
C.在起始授权机构(SOA)记录为区域设置增加刷新间隔
D.在该区域的DNS主服务器的属性选项中禁用网络掩码排序

其中,因为滞后支出变量,第一个可用年份(基年)是1993年。
(i)用混合OLS估计模型,并报告通常的标准误。为使得ai的期望值可以非零,你应该与年度虚拟变量一起包含一个截距项。支出变量的估计效应是什么?求OLS残差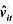 。
。
(ii)lunchit系数的符号在意料之中吗?解释系数的大小。你认为学区的贫穷率对考试通过率有很大的影响吗?
(iii)利用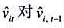 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
(iv)现在用固定效应法估计方程。滞后的支出变量仍显著吗?
(v)你为什么认为在固定效应估计中,注册学生人数和午餐项目变量不是联合显著的?
(vi)定义支出的总(或长期)效应为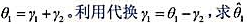 的标准误。
的标准误。
















