

 如果结果不匹配,请
如果结果不匹配,请 

 更多“通常将元素的比较和移动操作视为排序算法的基本步骤。()”相关的问题
更多“通常将元素的比较和移动操作视为排序算法的基本步骤。()”相关的问题
对于几乎有序的向量,如教材代码2.26(60页)和代码2.27(60页)所示的起泡排序算法,都显得效率不足,比如,即便乱序元素仅限于A[0,√n)区间,最坏情况下仍需调用bubble()做Ω(√n)次调用,共做Ω(n)次交换操作和Ω(n3/2)次比较操作,因此累计运行Ω(n3/2)时间。
a)试改进原算法,使之在上述情况下仅需o(n)时间;
b)继续改进,使之在如下情况下仅需o(n)时间:乱序元素仅限于A[n-√n,n)区间;
c)综合以上改进,使之在如下情况下仅需o(n)时间:乱序元素仅限于任意的A[m,m+√n]区间。
中值相对较小的数据会像水中的气泡一样逐渐上升到数组的最顶端,与此同时,较大的数据逐渐地下沉到数组的底部。这个处理过程需要在整个数组范围内反复执行多遍。每一遍执行时,比较相邻的两个元素,若顺序不对,则将其位置交换,当没有数据需要交换时, 数据也就排好序了。编程将排序函数DataSort() 改用冒泡法实现。
如果在合并排序算法的分割步骤中,将数组a[0:n-1]划分为[ ]个子数组,每个子数组中有O(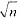 )个元素,然后递归地对分割后的子数组进行排序,最后将所得到的[ ]个排好序的子数组合并成所要求的排好序的数组a[0;n-1].设计一个实现上述策略的合并排序算法,并分析算法的计算复杂性.
)个元素,然后递归地对分割后的子数组进行排序,最后将所得到的[ ]个排好序的子数组合并成所要求的排好序的数组a[0;n-1].设计一个实现上述策略的合并排序算法,并分析算法的计算复杂性.
构造轴点的另一更为快捷的策略,思路如图x12.1所示:

初始时取k-1=mi=lo,L和G均为空;此后随着k不断递增,逐一检查元素V[k],并根据V[k]相对于候选轴点的大小,相应地扩展区间L(图(d))或区间G(图(c)),同时压缩区间U。最终当k-1=hi时,U不含任何元素,于是只需将候选轴点放至V[mi],即成为真正的轴点。
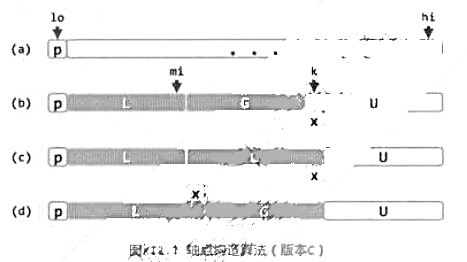
a)试依此思路,实现对应的划分算法vector::partition();
b)基于该算法的快速排序是否稳定?
c)基于该算法的快速排序,能否高效地处理大量元素重复之类的退化情况?
















